Paper
Introduction
Feature Bagging은 supervised learning에서 널리 사용되는 Bagging 아이디어에 착안하여 High-Dimensional 데이터에서 Unsupervised learning 관점으로 Outlier를 탐지하는 새로운 방법을 제안합니다.
Motivation
기존 outlier detection 방법론의 경우 데이터의 전체 변수 (full-dimension)를 모두 이용해 이상치를 탐지합니다. 하지만 이 방법을 High-dimensional 데이터에 그대로 적용할 경우 두가지 문제가 발생합니다.
첫째, 'Data sparsity'. [2]에 따르면 데이터의 object를 공간상에 표현할 때, 차원이 추가됨에 따라 object간의 거리가 멀어지고 결국 모든 object간의 거리가 비슷해집니다. 이는 차원의 저주 (curse of dimensionality)라고 불리기도 합니다. 이 특성이 outlier detection에 있어 문제가 되는 이유는 대부분의 outlier detection 방법론이 한 object가 다른 대다수의 object 혹은 집단과 떨어진 정도 (deviation)를 기준으로 outlierness를 계산하기 때문입니다. 차원이 매우 큰 High-dimensional 데이터의 경우 object간의 거리는 모두 비슷해져 outlierness 계산에 더이상 의미있는 정보로 사용될 수 없습니다.
둘째, 'Local feature relevance'. object의 outlierness는 전체 변수 중 일부 변수들의 조합에서 더 잘 나타나기도 합니다 (only the subset of attributes is useful for detecting anmalous behavior). 전체 변수 (full-dimension)에는 outlierness를 평가하는데 방해가 되는 irrelevant attributes가 포함되어 있는 경우가 있기 때문입니다. 예를들어, 아래의 Figure 1을 보면 object ●의 outlierness는 변수 {1,2}의 관점에서 더 잘 드러나는 반면, object ■의 경우엔 변수 {3,4}의 관점에서 더 잘 나타나는 것을 알 수 있습니다. 또한, {1,2}에 {3}을 추가하여 만든 {1,2,3}에선 {1,2}에서 관측되던 object ●의 outlierness가 더이상 보이지 않는 걸 확인 할 수 있습니다. 즉, 차원이 늘어남에 따라 더 낮은 차원에서 관측되던 outlierness가 오히려 가려지는 경우가 생기는 것입니다.

Basic Idea
Feature Bagging은 위의 두 문제를 극복하기 위해 전체 변수 중 일부 변수들을 임의로 추출하여 새로운 데이터셋을 만들고 그 데이터셋에 대하여 (full-dimension을 이용하는) classical outlier detection 모델을 적용합니다. 이러한 적합 과정을 T번 반복한 후, T개의 outlier score vector를 combine 하여 최종 outlier score를 도출합니다.
이는 surpervised learning에서 predictive modeling에 널리 사용되는 Bagging, 그 중에서도 Random Forest의 방법과 매우 유사합니다. Random Forest는 전체 데이터 중 일부 샘플 (observatoin)들을 임의로 T번 추출하여 T개의 데이터셋을 만들고 각 데이터셋에 대해 Decision tree (CART) 모형을 적합하는 데, 이 때 각 Tree split에 사용되는 변수의 개수를 제한하여 T개의 tree간의 correlation을 낮췄습니다. 각 Tree에 대한 적합이 끝나면, 모든 Tree에 적합된 prediction 결과를 combine하여 최종 결과로 채택합니다.
Feature Bagging의 경우엔 observation sampling을 하지 않고 변수들만 임의로 추출하여 데이터셋을 만든 후 각 데이터셋에 classical outlier detection (논문에선 LOF[4] 사용) 모델을 적합하여 각 object에 대한 outlier score를 얻습니다. 이 과정을 T번 반복한 후 그 결과를 combine하여 최종 outlier score로 채택합니다.
Algorithm
앞서 설명한 내용을 algorithm으로 나타내면 다음과 같습니다. 설명드리지 않은 내용 중 algorithm에 기재된 부분은 2가지 입니다.
첫째, '임의추출하는 변수의 개수'. T개 데이터를 만들 때, 추출하는 변수의 개수는 (d/2, d-1)사이의 값으로 랜덤하게 정해집니다. 따라서 T개의 데이터 construction에 사용되는 변수 개수는 각기 다를 수 있습니다.
둘째, 'Combination function'. T개의 데이터에 classical outlier detection 모델 (이 경우, LOF[4])을 적합하여 얻은 T개의 outlier score vector를 combine 하는 방법으로 이 논문은 2가지를 제안합니다. Breath-First 방법과 Cumulative sum 방법입니다. 이 두가지 combination function은 다음파트에서 설명드리도록 하겠습니다.

COMBINE() function
(i) Breath-First
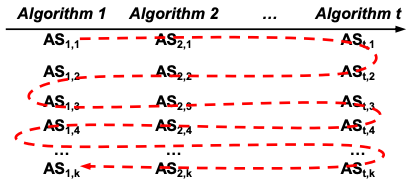
Breath-First 방법은 T개의 outlier score vector에서 1위를 차지한 (outlier score가 가장 높은) object들을 우선적으로 찾습니다. 이 object들의 index를 새로운 벡터에 저장하고 그 다음 순위에 위치한 (2등을 한) T개의 object들을 새로운벡터의 마지막에 배치합니다. 위 과정을 1위부터 마지막 순위 (sample 개수) 만큼 진행합니다. (새로운 벡터에 object의 index를 저장할 때, 중복된다면 나중에 발견된 object를 저장하지 않습니다)
이해를 돕는 그림과 algorithm을 Figure3과 Figure4에서 확인할 수 있습니다.

(ii) Cumulative Sum
T개의 outlier score vector를 observation 기준으로 더합니다. 즉, 한 object의 최종 outlier score가 Feature Bagging을 통해 얻은 T개의 outlier score를 전부 합한 값으로 결정됩니다.

Discussion
Feature Bagging의 outlier detection 성능은 [1]에서 확인하실 수 있습니다.
Feature Bagging의 장점은 다음과 같이 정리할 수 있습니다.
- High-dimensional 데이터에서 발생하는 2가지 문제 (data sparsity, outlier behavior only in the local subspace)를 개선할 수 있다.
- Random하게 subspace를 선택하기 때문에 computational cost가 적다.
단점은 다음과 같습니다.
- Subspace selection을 randomness에 의존하게 된다.
- Random하게 subspace를 선택하기 때문에 irrelevant attributes가 포함된 subspace에서의 결과가 최종 outlier score에 반영될 수 있다.
Reference
[1] Lazarevic, A., & Kumar, V. (2005, August). Feature bagging for outlier detection. In Proceedings of the eleventh ACM SIGKDD international conference on Knowledge discovery in data mining (pp. 157-166).
[2] Beyer, K., Goldstein, J., Ramakrishnan, R., & Shaft, U. (1999, January). When is “nearest neighbor” meaningful?. In International conference on database theory (pp. 217-235). Springer, Berlin, Heidelberg.
[3] Müller, E., Schiffer, M., & Seidl, T. (2011, April). Statistical selection of relevant subspace projections for outlier ranking. In 2011 IEEE 27th international conference on data engineering (pp. 434-445). IEEE.
[4] Breunig, M. M., Kriegel, H. P., Ng, R. T., & Sander, J. (2000, May). LOF: identifying density-based local outliers. In Proceedings of the 2000 ACM SIGMOD international conference on Management of data (pp. 93-104).



